This two-part article explores related tools and technologies that biopharmaceutical companies can leverage to build an efficient mechanism for capturing and delivering valuable information. In BioProcess International’s December 2009 issue, part 1 of the series focused on infrastructure selection and how hardware, software, and information systems form a kind of ecosystem (1). Simplicity, sustainability, and scalability can be achieved only when that trio is designed holistically. Part 1 further explored structured data capture and analysis tools, whereas this second half is dedicated to unstructured data capture and analytics. Part 2 concludes by focusing on how an integrated environment can be created to leverage on both structured and unstructured data, providing a single access window to enterprise information for end users.
A GMP/GLP Environment
Currently the major portion (estimated >80%) of the knowledge space within a biopharmaceutical organization exists in unstructured form (free-form text and documents). This type of data lacks defined structure and schema (like the rows and columns of structured data) needed to make it easily interpretable by machines, so this is difficult to query and search. Unstructured data tools bring some level of structure and format to such highly unorganized information. At the same time, such tools provide an efficient and easy way to capture, share, and search through these data.

Before actually discussing unstructured data tools, it is important to understand the work processes that contribute toward most unstructured data and how they relate to one another. One such conglomerate of work processes is formed by the current good manufacturing practice (CGMP) and current good laboratory practice (CGLP) systems.
CGMP Systems: In the biopharmaceutical industry, much unstructured data comes from CGMP quality systems in which various work processes — such as corrective and preventive actions (CAPAs), nonconformance, training management, and standard operating procedure (SOP) revisions — involve creation of many documents. As Figure 1 shows, work processes within quality systems are linked to the central process of document management and control. They mainly involve task assignment, tracking, review, and approvals. So they require a good workflow engine that can route documents and issues through a well-defined cycle while capturing knowledge and events generated at each stage. There are two approaches to managing QA system work processes: prepackaged solutions and custom builds.
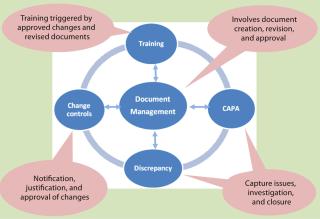
The first approach involves implementing a prepackaged quality management solution specifically designed for GMP requirements. These solutions cover every aspect of quality management, from document management to training and investigation. One major benefit of this approach is that prepackaged solutions provide a single interface and integrated work flow for all interconnected work processes, which helps in efficient closure of issues related to the quality management. High costs involved in this route can make it unsuitable for the small to medium-sized enterprises, however. Two major players in this field are Master Control, Inc. (www.mastercontrol.com) and Trackwise software from Sparta Systems (www.sparta-systems.com).
The second approach is to assemble the different building blocks of a CGMP quality system (Figure 1) using independent solutions and integrating them. Typically this can be accomplished with a good document management system, a good issue tracker system, and/or a good workflow engine. The document management system takes care of document control, and the issue tracker can be used for tracking activities related to CAPAs, nonconformance, and change controls. Integration is the major challenge in this approach. Many open-source alternatives are available in this field, however, which makes it a viable option for small and medium-sized enterprises. Alfresco (www.alfresco.com) and Knowledge Tree (www.knowledgetree.com) provide good solutions for document and content management. The Request Tracker program from Best Practical Solutions, LLC (http://bestpractical.com/rt) offers a good solution for issue tracking and workflow management. ProcessMaker (www.processmaker.com) and Jira software from Atlassian Pty Ltd. (www.atlassian.com/software/jira) are a couple of other issue-tracking workflow engines offered as open source and for commercial license, respectively.
CGLP Quality Systems: Similar to the CGMP environment for manufacturing are CGLP work processes in research and development that involve documented experiments in laboratory notebooks, technical memos, and reports. These can be managed similarly to CGMP systems. Both mainly revolve around the creation, control, and workflow of documentation. Unstructured data tools (explained below) can play a major role in making document creation (authoring) itself an efficient process capable enough of handling control and work flow in an integral process.
Unstructured Data Tools
This section overviews the tools that can help make document management efficient. They can be broadly divided into three main categories: Web-based authoring tools, enterprise 2.0 tools, and XML-based tools. A company can choose from tools within these categories to cover its own unstructured knowledge space depending upon the type of legacy applications involved.
Web-Based Productivity: Authoring tools (or office productivity tools) are applications that allow for viewing, creating, and modifying general office documents (e.g., presentations and spreadsheets). Traditionally, this the realm of desktop applications such as the Microsoft Office suite. However, those suffer from various drawbacks including cost, difficulty in sharing and collaborating, platform dependency, and a lack of underlying metadata or structure. By contrast, a whole new breed of Web-based office tools available at much lower cost offers improved collaboration with the same security.
Most browser-based tools are platform independent replicas of legacy office tools on the Web. However, some can provide a first step in transitioning from legacy desktop applications to Web-based tools:
- Google Docs (http://docs.google.com), available as an online service from Google, provides a simple interface for creating and editing documents. Its collaboration and sharing options are noteworthy. Searching documents is also easy, using Google’s search engine to make finding documents fast.
- Zoho (www.zoho.com), like Google, is an online service that provides various productivity and collaboration applications. It is one of the most comprehensive Web-based office suites available.
- OpenGoo (www.opengoo.com) is open-source software that provides collaboration, communication, and productivity tools all bundled in the same package. Unlike Zoho and Google, it can be installed on a corporate intranet.
Enterprise 2.0 Tools: In the next step, companies can try to leverage “enterprise 2.0” tools for better collaboration and knowledge management. The following types of tools can help. Table 1 summarizes key differences between legacy office tools and Web office tools (2).
Table 1: Comparing legacy with Web-based office tools

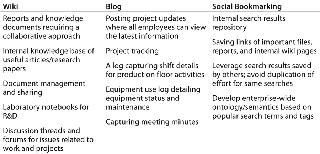
Wikis and blogs provide an easy way to capture work-related knowledge and promote easy collaboration and knowledge sharing within an organization. Wikipedia (www.wikipedia.org) best illustrates the power of collaborative writing.
Wikis enable quick content creation in which all team members can simultaneously work on the same document. This ensures that everybody has the latest information and can work together. Once a document is complete, different people within an organization can give feedback on it for an easy discussion in creating a knowledge-base. An added benefit is easy accessibility. A wiki/blog website can be accessed through any browser without the need for complex software installation. Wiki tools worth exploring are Screwturn (www.screwturn.eu) and XWiki (www.xwiki.org). The Cynapse (www.cynapse.com) integrated package is an evolved platform for collaboration that includes wikis, blogs, and document management.
Social bookmarking enables users to save relevant bookmarks with their own keywords and descriptions, making them available for rest of their organization to search. This builds an internal repository of useful websites for employees. Instead of using an external search engine to find relevant results from all over the web, employees can go directly to an internal bookmarking site and access the most relevant information saved by their colleagues. This saves time otherwise spent searching. It proves useful for intranet sites as well because employees can link to important graphs and reports generated from database queries. Other employees interested in the same information can find those reports on the social bookmarking site. Table 2 lists some of these tools/sites, and Table 3 lists potential applications of “enterprise 2.0” tools in the biopharmaceutical knowledge space.
Table 2: Social bookmarking tools

Table 3: Potential use cases of enterprise 2.0 tools
XML–Based Authoring Tools: Extensible mark-up language (XML) is an open standard managed by World Wide Web Consortium (www.w3.org) that enables generation of richly structured documents and defining content as a set of various components rather than one monolithic document (3). The components can be defined once and linked to other documents for reuse for easy creation of documents that otherwise can involve cutting and pasting the same content over and over.
For example, CGXP documents (SOPs, batch production records, and reports) typically include certain sections (e.g., headers, footers, precautions, and process descriptions) that are common across many documents. Those sections are traditionally repeated every time a new document is created by cutting and pasting from earlier documents. Whenever one is changed, all documents must be rewritten to incorporate the change(s). Not only does this involve much time and human effort, but it is also prone to errors. All this can be managed in a more efficient way by creating documents in XML with repeatable sections written only once and linked to all documents. A change is made only once, and all linked documents are updated automatically. So XML-based authoring makes content creation easier and facilitates version control.
Some level of in-house knowledge about XML can enable an organization to leverage upon this technology’s potential benefits. Table 4 lists some tools that can help you move toward XML-based document management. XML-based document authoring can help companies migrate toward XML-based common technical documents (CTDs) for electronic submissions mandated now by many regulatory agencies.
Table 4: XML-based authoring tools

The Way Forward
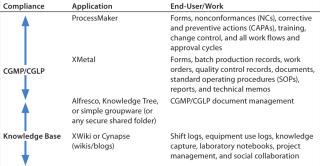
The way forward for biopharmaceutical companies in the battle to manage unstructured data is tightly integrated authoring, work flow, and document management. Different tools in each category can be integrated to cover the whole gamut of CGXP work processes for the complete lifecycle management of documents from the authoring stage until they become obsolete. Figure 2 summarizes these tools.

Table 5 indicates where each tool fits in from an end-user and compliance perspective. The “enterprise 2.0” tools can be easily used for free-form contextual knowledge-capturing with collective and collaborative authoring. For CGXP, document management solutions can be used for storage, control, and life-cycle management of documents. They can be authored directly in XML with the help of XML authoring tools that allow reuse of content to prevent duplication of effort. Finally, tracking can be handled by workflow engines.
Table 5: Perspectives on unstructured data and tools
Search Engines: One basic requirement for unstructured documents is that they be searchable. Search engines add this new capability by creating keyword indexes within documents and then returning ranked document lists in response to user queries. This facilitates searching, which may otherwise require indefinite drilling down through shared folders or manually checking each document to find required information. One major player in enterprise search engines is of course Google search (www.google.com/enterprise/search/index.html), which is easier to set up and deploy than many sophisticated and complex alternatives.
Integrating Structured and Unstructured Data — the Web Services Way: An integrated platform for information management can be designed as a web service application in which network service is leveraged to deliver information. This enables a single window of access to all information (both structured and unstructured), a main design goal. The back end of this web service application can be XML, which integrates multiple data sources by providing a platform-independent (both hardware and software) data representation (4). This helps reducing complexities in data exchange between incompatible applications. Once information is in XML format, it can be transformed into various display formats, so XML combined with HTTP can serve as a “backbone” for delivering data to end users. As Figure 3 shows, a web service architecture can be layered, with each layer having a specific function in making information available over a network.
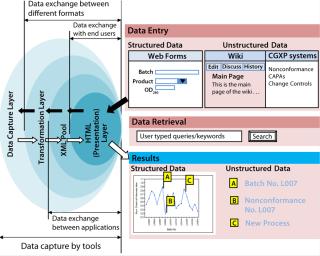
A data capture layer provides an efficient mechanism for collecting and capturing structured and unstructured data using a range of tools and technologies. The tools may be different depending on the kind of data, but for end users a simple browser should start the process of data capture. This layer typically consists of web-enabled databases and data historians (1).
Transformation Layer: Data captured in the first layer lacks a common language, which makes it difficult for both kinds of data sources to communicate with each other. This is where transformation layer comes in to create a common vocabulary and language so exchange can take place across different formats. It should convert information coming from the data capture layer into one common language and format. Typically, this transformation is accomplished with ASP.NET and Java components, PHP scripts, and text annotation and tagging tools, all capable of converting data coming from various sources into one common XML format according to predefined schema.
An XML Pool acts as a repository for all kinds of data in the same structure. This layer enables data exchange across applications to provide both context and content together. It also acts as a back-end layer for achieving a single version of the truth by bringing together disparate data structures into a common language and structure.
HTML (Presentation Layer): Data coming from an XML pool are converted to HTML using XSLT. The resulting layer serves information to end users. They need only a browser for both data capture and data retrieval instead of juggling between various desktop applications. A search interface can be provided in which user-typed queries and keywords enable retrieval of relevant results from both the structured and unstructured domains.
Key to the Future
XML-based technologies are key to the future for knowledge-intensive industries to manage knowledge efficiently, and they should help bring knowledge closer to where it is needed. This will lead to faster business decisions, faster product improvement cycles, and overall enterprise efficiency. The FDA’s quality-by-design (QbD) and process analytical technology (PAT) initiatives will benefit significantly from XML-based information infrastructure. By building in-house XML capabilities, companies can implement highly customizable, inexpensive tools that can easily replace underused, traditional, monolithic, one-size-fits-all, off-the-shelf applications.
REFERENCES