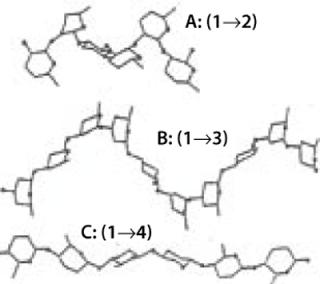
A polysaccharide is a complex glycan with at least 10 monosaccharide units. It can be formed by the multiples of the same monosaccharide (a homopolysaccharide) or by two or more monosaccharides combined (heteropolysaccharide). Two homopolysaccharides can have completely different conformations — and thus properties — based on the position and type of glycosidic linkages in the structure (Figure 9). Polyglucose ranges from cellulose — β(1,2,3,4) glucan, with its zig-zag chains regularly superimposed to each other and bound tightly by hundreds of hydrogen bonds to form strong fibrils that confer structural strength to standing trees — to flexible α(1,2,3,4,5,6)-glucans with twirling structure and high solubility, which are typically used by plant seeds as a nutrient during early development.
PRODUCT FOCUS: G
When a carbohydrate (a simple monosaccharide, a long polysaccharide chain, or a complex branched oligosaccharide) is linked to a protein or peptide, a lipid or any other moiety, the resulting molecule is called a glycoconjugate. They can be called glycoproteins, glycopeptides, or glycolipids depending on the nature of the moiety binding with the sugar. Monosaccharides containing other noncarbohydrate substituents (e.g., phosphates, sulfates, acetates, lipids, or peptides) are often found in nature.
More details on the topics covered here can be found in references 1,2,3,4, and recommendations on the nomenclature of glycoconjugates can be found in reference 5,. Part one of this article examined basic carbohydrate chemistry, and Part three will conclude it with a discussion of carbohydrate markers and tools for bioprocess monitoring.
Glycoconjugates of Mammalian Cells and Their BiosynthesisIn mammalian organisms, each group of naturally occurring glycoconjugates contains a limited number of monosaccharide units. Even so, because the biosynthesis of glycans does not follow a genetic “code” (like the biosynthesis of proteins does), many variations are possible — thus leading to glycan heterogeneity. Glycan biosynthesis is controlled by the specific expression of glycosyltransferases and glycosidases in each cell as well as
-
substrate availability
-
cellular competition for a common substrate
-
subcellular membrane organization
-
rate of transit through the endoplasmic reticulum (ER) and/or Golgi body
-
pH and ions.
Glycoproteins contain two basic types of carbohydrates, N-glycans and O-glycans, according to the peptide–glycan linkage region (Figure 10).
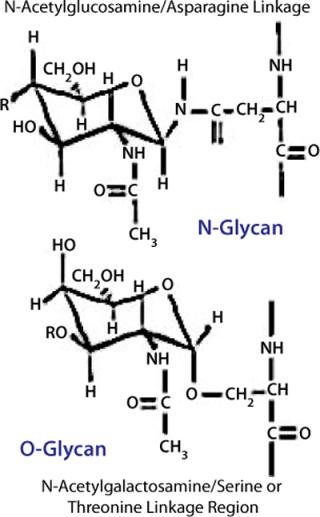
Biosynthesis of N-glycans is mediated by a lipid-linked precursor transferred en-bloc to proteins in the ER, followed by sequential addition and removal of monosaccharide residues throughout the Golgi apparatus. Each glycosylation reaction uses activated monosaccharides (sugar nucleotides) as donors, is catalyzed by a glycosyltransferase, and has specific needs regarding pH and ions. Removal of monosaccharides is effected by glycosidases. N-linked glycosylation requires a consensus sequence for each sugar to be attached to the peptide (Asn-X-Ser/Thr).
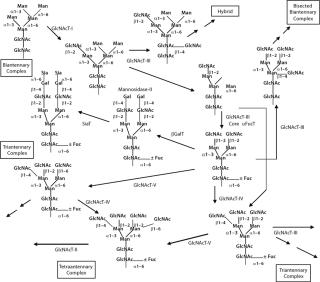
N-glycans have a common core region of Man3GlcNAc2. Three different types of branches originate from this core structure: high-mannose type, complex type, and hybrid type. These branches or antennas contain Gal in addition to Man and GlcNAc with specific types of linkages. The antennas can be terminated by Sia residues linked α(2, 3) or α(2,3,4,5,6) to the Gal. Both core and antennas can be fucosylated (α Fuc) in specific positions. Figure 11 depicts the possible diversification of N-glycan structures based on biosynthetic competition as described above.
Biosynthesis of O-glycans is much simpler by contrast, starting in the Golgi with the addition of GalNAc to Ser or Thr after a protein is folded and moving forward with sequential monosaccharide addition. More than eight core structures have been identified containing GlcNAc, GalNAc, Gal, Fuc, and Sia (Figure 12). Mucins are proteins that contain 50–80% carbohydrate by weight. Such structures are O-glycans varying in size from one to 20 residues and containing sulfate groups in addition to the common monosaccharides, which contributes to their highly negative charge (Figure 13). There are membrane-bound and secretory mucins. Secretory mucins constitute the viscous gel covering most surfaces of the respiratory, gastrointestinal, and reproductive tracts.
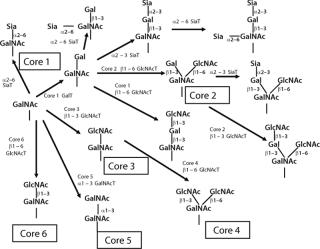
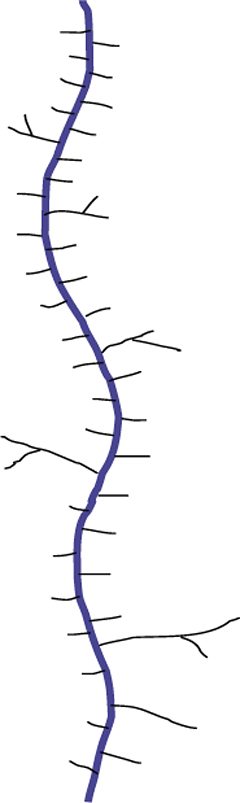
Figure 13:
Other types of highly charged glycoconjugates are proteoglycans (Figure 14) in which a central core protein is decorated with one or more linear, highly charged, polysaccharide chains called glycosaminogly can (GAG). All mammalian cells produce proteoglycans and these are secreted, stored in granules or inserted into the membrane. Each GAG is a polymer of disaccharides of a hexosamine (GlcNAc or GalNAc) and an uronic acid (GlcA or IdoA). These chains also contain sulfate groups at various positions. There are different types of GAG chains: dermatan sulfate, chondroitin sulfate, hyaluronan, heparin, and heparan sulfate.Hyaluronic acid is a free polysaccharide without sulfates. Keratan sulfate has the same type of linkage found in a glycoprotein. The rest of the GAGs are linked to a Ser on peptides through a core tetrasaccharide: GlcA-Gal-Gal-Xyl.
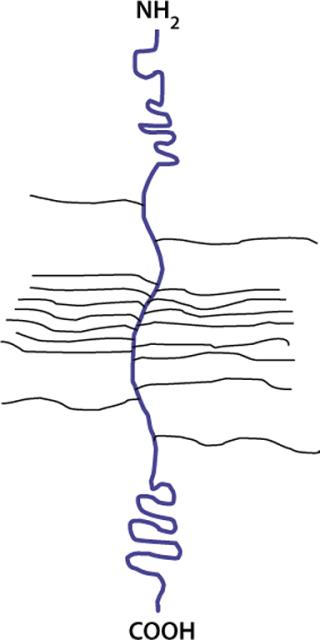
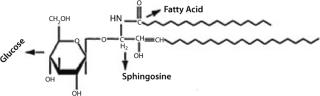
Glycolipids comprise two main classes based on their linkage region: glucosylceramides and galactosylceramides. The structures of glycolipid sugar chains are as diverse as those of glycoproteins, with some containing as many as 30–60 monosaccharide residues. Figure 15 shows a Glc-ceramide as example. As with O-glycans, biosynthesis occurs through sequential glycosylation reactions.
A type of glycoconjugate that combines lipid, protein, and carbohydrate moieties is the GPI-anchor. Many cellular membrane proteins are anchored by glycolipid structures called glycosylphospha-tidylinositols. The common core structure of a GPI-anchor consists of ethanolamine–PO4–6Man–α1-2Man–α1-6-Man–α1-4GlcN-α1-6myo–Ino-1–PO4–lipid. GPI biosynthesis occurs in two steps: first, preassembly of a donor GPI in the ER, followed by attachment of that GPI and cleavage of the carboxy-terminal peptide from the protein.
Although core regions are characteristic to each class of glycoconjugate, the external or terminal sequences among them show some similarities. For example, both glycoproteins and glycolipids can contain the terminal Sialyl Lewis X tetrasaccharide (Figure 16).
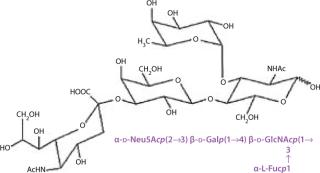
Some proteins or classes of proteins receive a specific glycosylation sequence not seen in others. Lysosomal enzymes contain mannose-6-phosphate on their high-mannose N-glycans, and α(2–8) polysialic-acid chains are attached to the N-linked glycans of neural cell adhesion molecules during embryonic development. Nuclear and cytoplasmic glycosylation also occur as with O-linked GlcNAc, fucose, and mannose. More details regarding glycoconjugates of mammalian cells and their biosynthesis can be found in reference 6,.
Characterizing Complex Carbohydrate StructuresThe profuse chemical diversity described so far cannot be handled with a universal analytical approach. A battery of strategies is required for full structural characterization. The building blocks of complex carbohydrates are structurally very similar to each other, and as such they are harder to differentiate than those of other biopolymers (e.g., amino acids). So thorough analysis of complex carbohydrates structures is still a major challenge — even with today’s technology capable of separating closely related structures and detecting them in a sensitive and specific manner.
Our molecular understanding of disease relies heavily on this type of chemistry exercise because the knowledge of structures leads to the understanding of their biology — and thus helps us find tools for intervention. As it has been for decades, the analysis of complex carbohydrate structures is typically left to those working in academic institutions or research groups of biopharmaceutical companies. Increasingly, however, regulatory bodies are recognizing that carbohydrate analysis can in some cases provide critical information about biopharmaceutical product characteristics related to comparability and manufacturing consistency. The WCBP CMC Strategy Forum focused on this subject in January 2007 (7).
A detailed description of the structural features of a carbohydrate-containing biomolecule is increasingly part of the expected content for a new drug application or comparability protocol for a biotechnology product. This type of analysis requires a high level of technical expertise, powerful instruments (e.g., mass spectrometers with high accuracy and sensitivity, NMR spectrometers) and a considerable amount of time as well as an appropriate quantity of sample material. Picomolar quantities are sufficient for composition and linkage analysis using a variety of HPLC and CE methods combined with enzymatic treatments and/or MS approaches, but sequence or linkage information requiring NMR analysis would involve nanomolar quantities.
The “popularity” of carbohydrates at the beginning of the 20th century, when polysaccharide use was profuse across several industries (from oil extrusion to food additive
s), was mainly based on the flourishing of analytical approaches based on breaking up carbohydrate structures, then detecting and quantitating the pieces to put them back together. Such analytical methods were enabled by technical advances in chromatography (e.g., gas–liquid chromatography with flame-ionization detection, GLC-FID). All those methods were laborious, and they required strong reagents and many hours of manual review of results — even manual calculations. The breaking apart and regrouping involved inherent error, so the outcomes were imperfect. Use of these methods, however, led to progress in related industries (e.g., fractionation of polysaccharide additives with different rheologic properties).
As the 21st century begins, new enabling technological advances are in the fields of data collection and processing as well as robotics. Many samples taken and manipulated in replicates (high throughput) provide more reliable results with less manual effort than before. Powerful data systems handle in seconds large volumes of data even from remote locations. Complex mathematics are accessible, and their incorporation in routine testing has become effortless to operators. These tools have been in use for several years in disciplines such as genomics and proteomics, and their use in the glycomics field has just begun. There is opportunity for developing new analytical tools that will initially be in the hands of experts but eventually will be “democratized” based on historical teachings.
Powerful data collection and processing capabilities also enable an increasingly popular trend of looking at the whole without breaking it up into pieces. Many errors found in the early 20th-century descriptions of large biomolecules resulted from artifacts produced by cleaving chemistry. High-field NMR spectrometers can now look at large, soluble glycoproteins using two-, three-, and even four-dimensional experiments that provide hundreds of thousands of data points. Within the resulting data forest, we can narrow down to areas that show native chemistry. This field, however, still requires a great deal of specialized expertise.
The present state of glycoanalysis is characterized by “smart” use of old knowledge (carbohydrate chemistry), old tools (e.g., enzymes and lectins), existing analytical strategies (HPLC, CE, a variety of MS types, and NMR), and new mathematical algorithms all coupled with powerful data collection and analysis systems.
To demonstrate the quality and consistency of glycoprotein manufacturing processes, certain aspects of a product’s carbohydrate structures can become useful parameters to monitor. When the appropriate product characterization studies have been performed, and the right analytical tools have been selected, these “reporter features” can be evaluated reliably and systematically. The corresponding methodologies can be validated and these methods implemented even in quality control environments. Good analytical chemistry expertise and standard instrumentation are sufficient for implementing such analyses as long as the “reporter features” are properly selected and understood. The key is to establish what knowledge is necessary and how accurate it needs to be.
Glycosylation analysis will be addressed in the concluding installment of this three-part article, along with its use in bioprocess monitoring.